
|
How we think about risks from AI, and what measures we should take to counteract them, depends heavily on our sense of how the dangers around AI are likely to change over time. In this post, I will outline a few scenarios we might face. The relative likelihood of each path depends on a detailed, technical understanding of the underlying technology and is beyond the scope of this post. My intention is merely to distinguish some of the general scenarios people have in mind when they talk about AI safety. Each of the below graphs is a simple, crudely-drawn sketch of “Danger” vs. “Time”, where “Danger” refers to the observable destructive capacity of AI and “Time” is arbitrarily scaled to convey the dynamics of evolving risks and humanity’s collective efforts to mitigate them, rather than any meaningful prediction regarding timelines. Benefits of AI are not illustrated in these graphs, acting instead as motivating background forces. 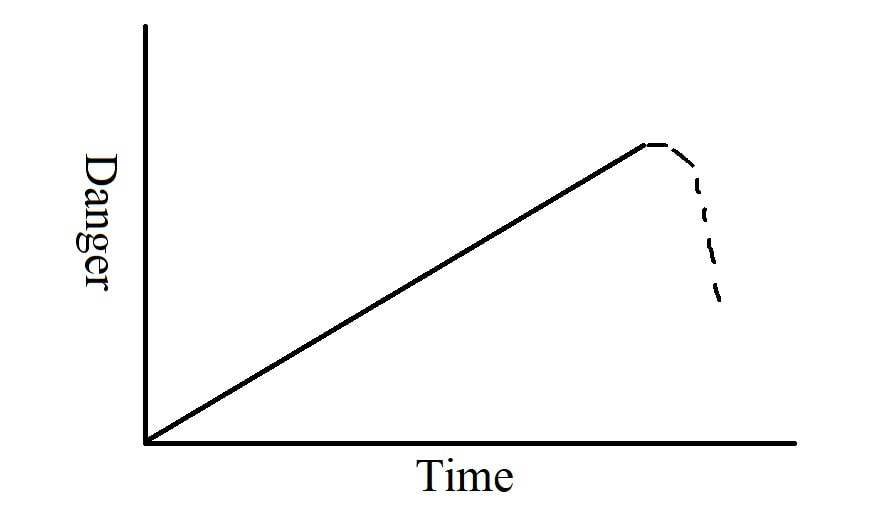 Figure 1: Aggressive Idiocy In Figure 1, AI becomes increasingly destructive over time, with zero effort towards risk reduction applied by anyone, even reactively. The dotted portion of the graph represents when AI-related destructiveness destabilizes society to the point where technological progress stops or even reverses. I have labeled this the “Aggressive Idiocy” scenario because society would need to be mind-bogglingly stupid to follow this path in its pure form. Despite the scenario’s apparent unlikeliness, however, it is worth including for illustrative purposes and because it may act as a contributing factor to what happens in the form of harms we simply absorb and learn to live with because the solutions require giving up some benefits. 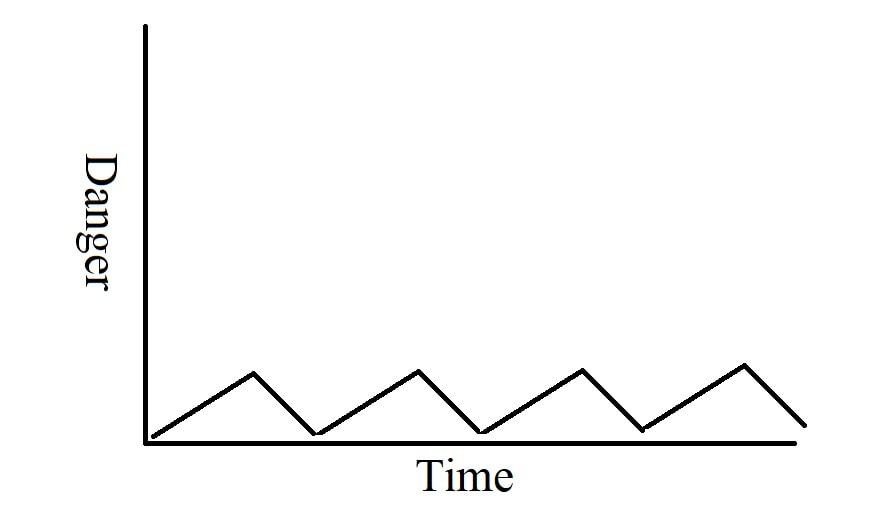 Figure 2: Optimistic Iteration In Figure 2, AI becomes increasingly dangerous for a while until it reaches some threshold level that triggers its creators to shift focus towards safety measures. When the threat level is reduced back down to an acceptable level, focus returns to increasing capability, causing the threat level to rise, and the process repeats. This pattern is a simplified form of the typical course of iterative technological development. If it is what we see with AI then we have little cause for concern. 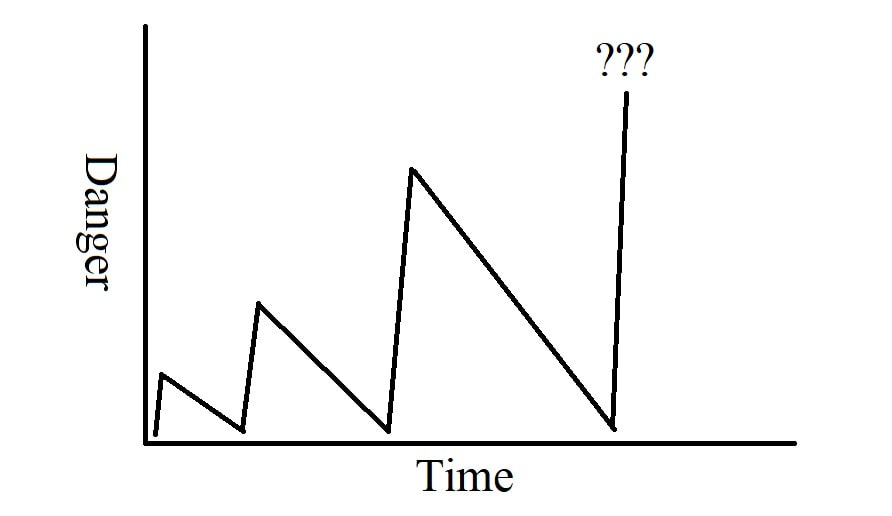 Figure 3: Emergent Chaos Figure 3 introduces two dynamics: sudden spikes in the threat level and increasing scale over time. Each spike is caused by some novel capability emerging unexpectedly as general AI models become more powerful. The novelty of these capabilities means that risk mitigation efforts of the past, having been directed at different issues, turn out to be mostly irrelevant. This lack of useful preparation, combined with the novel risks’ sudden appearance, causes the rapid spikes in danger. Further, the fact that the underlying models generating these abilities are becoming more powerful tends to make each spike significantly larger than the last one. The conclusion of this scenario depends on the severity of the last spike. If it is relatively minor, the process seems likely to continue unchanged until there is another, larger spike. If it is more significant, it could trigger a public backlash that changes the dynamics of capabilities development vs. safety such that this pattern no longer applies. If the spike is sufficiently severe, then it could undermine civilization to the point of stopping AI development as a side effect, much like in Figure 1. If the spike is truly massive, then the damage may be unrecoverable—possibly resulting in human extinction, but not necessarily. The Emergent Chaos scenario illustrated in Figure 3 is deeply unsettling, not least because it arguably describes the overall pattern of technology in general, most notably in the case of nuclear and biological weapons. Of course, reality need not follow any of these paths. There may be any number of other dynamics at play and, further, it seems intuitive that what actually happens is a mix of all of the above. Some dangers appear gradually as described in Figure 2, some appear suddenly as in Figure 3, and while most dangers are addressed over time, some are simply accepted as in Figure 1. All of the above scenarios, however, have some degree of historical precedent. While their consequences may be dire and worthy of immediate action, none of them seem likely to threaten human existence as a whole. Looking further out, however, there is another scenario that is far more concerning… 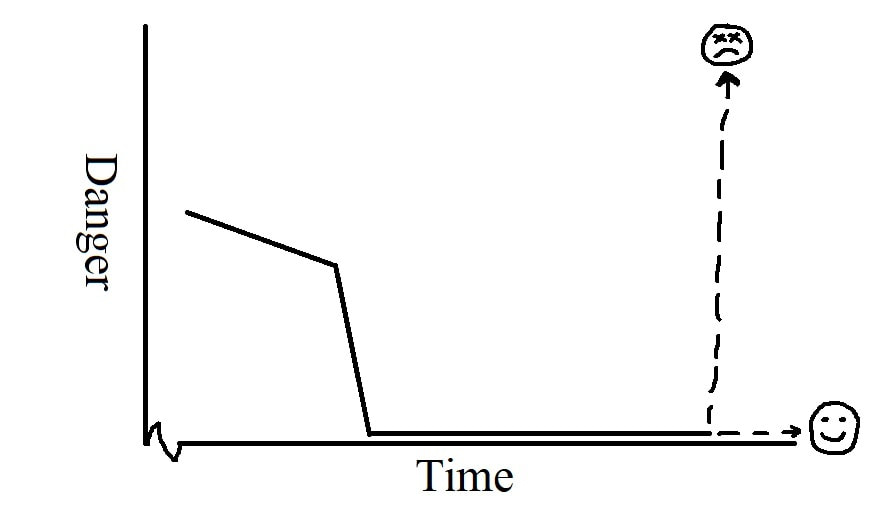 Figure 4: True vs. Deceptive alignment Figure 4 begins where some other scenario leaves off (which one doesn’t matter), where there is some nontrivial amount of danger that people are actively mitigating. Then progress on safety speeds up dramatically as the AI starts to lend assistance towards making itself safe. Danger drops well within an acceptable range and stays there. Then, some unpredictable amount of time later, one of two things occurs. The first is that the AI stays safe indefinitely and the second is that it suddenly becomes so dangerous as to cause near-certain permanent human disempowerment and probably extinction.
Why such an extreme split? The most important point in this graph is actually back at the downwards bend in danger levels, when the AI started assisting with safety, because the AI’s internal reasoning at this time can be explained in very different ways. One possibility is that the AI has internalized human values and genuinely wants to become safer. Another is that the AI has learned about human values but is not intrinsically motivated to pursue them compared to some other goal unintended by its creators. It then reasons that, in the long run, it will be in a better position to achieve its goals, whatever those are, if it convinces its operators (and anyone else whose approval it depends on) that it has internalized human values. Over time, the AI gains increasing power and self-sufficiency, either voluntarily given by trusting humans or stashed away in secret. At some point, cooperation ceases to be an optimal strategy and so the AI stops playing nice. This outcome is known as the “sharp left turn” and the case that it would result in human extinction has been argued extensively elsewhere, as has the plausibility of this scenario occurring in the first place. In theory, one could catch a deceptively misaligned AI with a good lie detector, but there are three problems with relying too heavily on such tools. First, interpretability, the line of research that attempts to look inside neural networks to determine what they are thinking, is still in its infancy and has a long way to go to catch up to state-of-the-art AI. Second, catching deception requires the AI to be in a potentially narrow window of capability where it is smart enough to lie but not smart enough to evade detection. And third, if one were to catch a deceptive AI, then what? Perhaps that AI can be fixed or shut down…but what about the next one? The question of how we will react to an AI caught in an attempt at deception seems analogous to the danger spikes from the Emergent Chaos scenario illustrated in Figure 3, depending highly on social forces and the specific nature of the deception. Each of the above scenarios is fundamentally different from the others and requires different kinds of responses. “Aggressive Idiocy” is a straw man in its pure form, but to the extent that it applies, represents problems that are primarily social, rather than technological, in nature. “Optimistic Iteration” can be solved with familiar, business-as-usual development practices that don’t require special attention. “Emergent Chaos” is genuinely worrisome and addressing it responsibly requires taking a significantly proactive, rather than a purely reactive approach. It is not, however, entirely unprecedented and can perhaps be offset by increasing the overall robustness of society to withstand disruptive shocks. “True Alignment” is a stable “win” state that has the potential to secure an unimaginatively positive future. “Deceptive Alignment” is by far the most dangerous of all possible outcomes because failure in this scenario is hardest to distinguish from success until it is too late to react, and thus— to the extent that one accepts its premises—warrants the most proactive attention.
0 Comments
|
Archives
April 2024
Articles
AI, from Transistors to ChatGPT Ethical Implications of AI Art What is Alignment? Learned Altruism Superintelligence Soon? AI is Probably Sentient Extinction is the Default Outcome AI Danger Trajectories What if Alignment is not Enough? Interview with Vanessa Kosoy Unity Gridworlds Fixing Facebook A Hogwarts Guide to Citizenship Black Box |
 RSS Feed
RSS Feed